 Data Quality
Data QualityIndicator “Uncertain missingness status”
Loading Tree…
Definition
No or uninformative missing value codes (e.g. NA/./Null…) appear where a qualified missing code is expected.
Explanation
This indicator has been introduced from the perspective, that an appropriately coded data set should have unambiguously interpretable data values in all of its fields.
A system indicated missing value refers to a technical aspect of the representation of data, for example “SYSMISS” in SPSS, “NA” in R, “.” in Stata. When occurring, this means that from the data set itself it cannot be concluded if this data value truly represents a missing value, something else or is just a consequence of a mistaken data management process. Even if from context knowledge it is known that a system indicated missing value represents a missing value it does not provide any information on why information is missing. Therefore any occurrence of a system indicated missing value may be regarded as a deviation from a properly designed data set.
Example
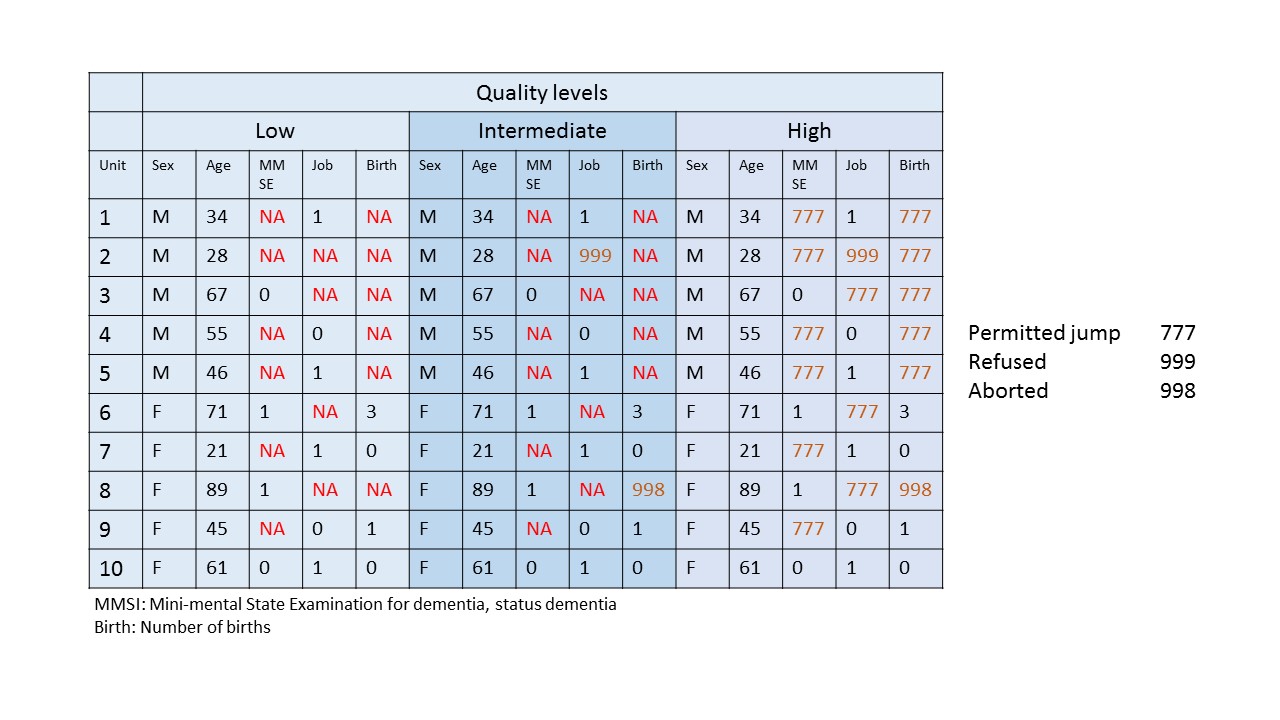
The presence of uninformative missing codes is illustrated in the subsequent graph which depicts an excerpt of an examination. I distinguishes three quality levels of coding. In the first part, low quality, there are only NA entries. For three variables, dementia according to the MMSE an instrument on dementia, job status, and number of births there are many missing values. However the reason is unclear.
In contrast in the right high quality coding example, all missing values have been assigned a code to explain reasons about missingness. It shows, that most of the missing values were due to permitted jumps. The item was not assessed based on design and therefore should not be treated as missing.
Guidance
Uninformative missing codes often represent missing data. However, the absence of some coding implicitly requires background knowledge to equate such codes or empty data fields and missing data. Uninformative missing codes may invalidate any completeness or correctness related findings for the affected data structures.
It is recommended to assign user defined data values to all data fields to enable unambiguous interpretations of the data.
Interpretation
The higher the number or percentage of occurrences the lower the data quality.
Implementations
Literature
Richter A, Schössow J, Werner A, et al. Data quality monitoring in clinical and observational epidemiologic studies: the role of metadata and process information. MIBE 2019;15(1).
