Introductory Tutorial
dataquieR’s workflow uses data and metadata for data quality reporting:

The main function for reporting is dq_report2, and this
tutorial shows how to use it.
Installation
The first step is to install dataquieR:
install.packages("dataquieR")Afterwards, we load it to use its functions:
library(dataquieR)Loading data and metadata
We can the load data using:
sd1 <- prep_get_data_frame("ship")This data set has 2154 observations and 33 variables:
View(sd1)| id | exdate | age | sex | obs_bp | obs_soma | obs_int | dev_bp | dev_length | dev_weight |
|---|---|---|---|---|---|---|---|---|---|
| 3861 | 1998-09-22 | 65 | 1 | 9 | 9 | 11 | 18 | 11 | 11 |
| 6506 | 1998-01-21 | 70 | 1 | 4 | 4 | 3 | 9 | 3 | 1 |
| 6096 | 1999-04-07 | 43 | 2 | 4 | 4 | 2 | 10 | 3 | 1 |
| 6674 | 2000-10-06 | 55 | 2 | 3 | 5 | 2 | 22 | 4 | 1 |
| 6490 | 1998-11-17 | 69 | 2 | 7 | 7 | 12 | 18 | 11 | 11 |
| 5366 | 1997-11-27 | 65 | 1 | 5 | 5 | 1 | 10 | 3 | 1 |
| 5735 | 1999-09-01 | 40 | 2 | 7 | 7 | 23 | 15 | 11 | 11 |
| 4031 | 1999-08-12 | 51 | 2 | 9 | 9 | 12 | 20 | 11 | 11 |
| 3578 | 2000-02-26 | 25 | 1 | 9 | 9 | 22 | 15 | 11 | 11 |
| 4807 | 2000-07-13 | 80 | 2 | 3 | 3 | 2 | 18 | 4 | 1 |
Next, we load the corresponding metadata using:
prep_load_workbook_like_file("ship_meta_v2")The metadata is a workbook containing several sheets or tables that can be called individually if needed.
For more information on the example data and metadata, see the example data description and the metadata tutorial.
Generating a report
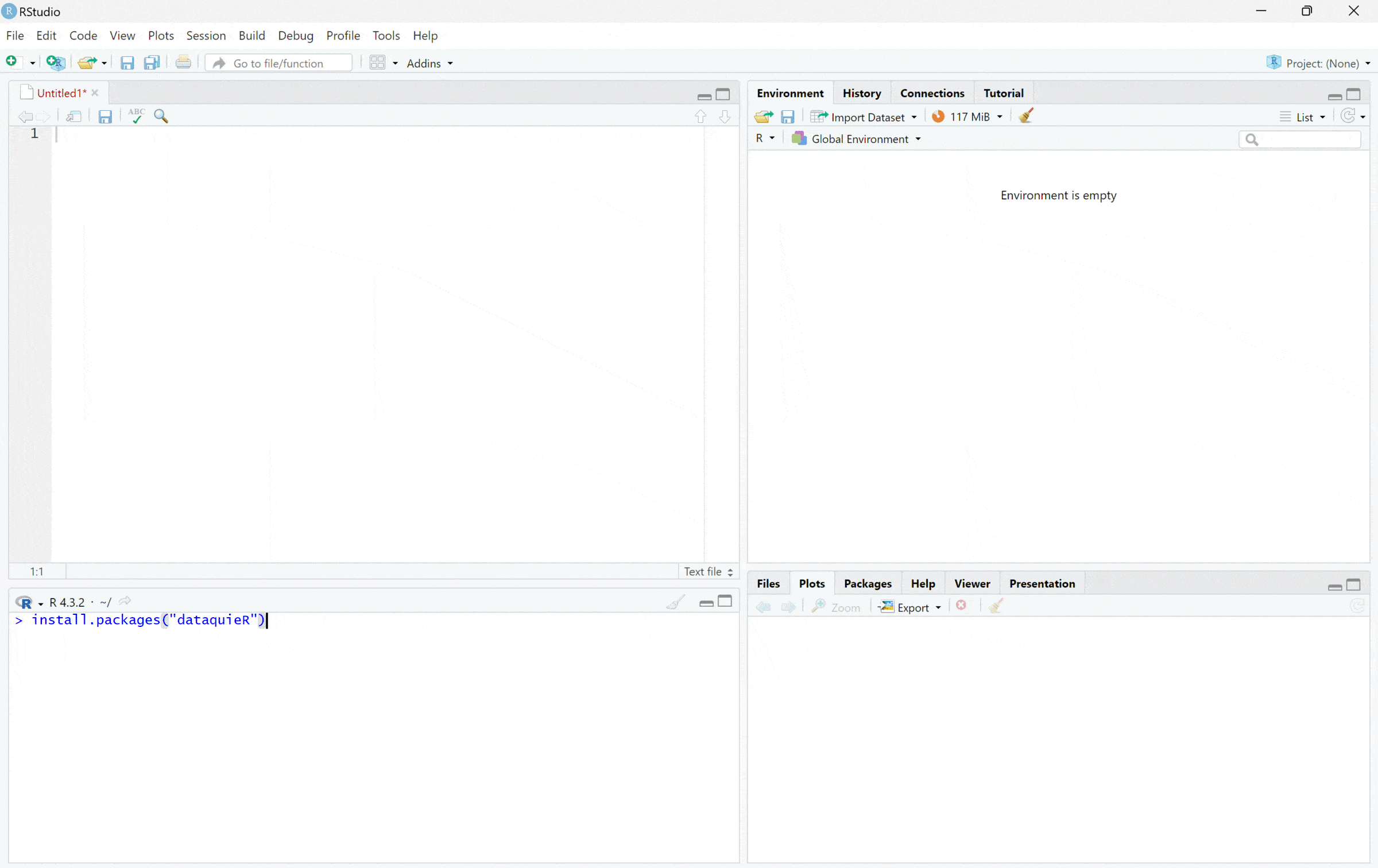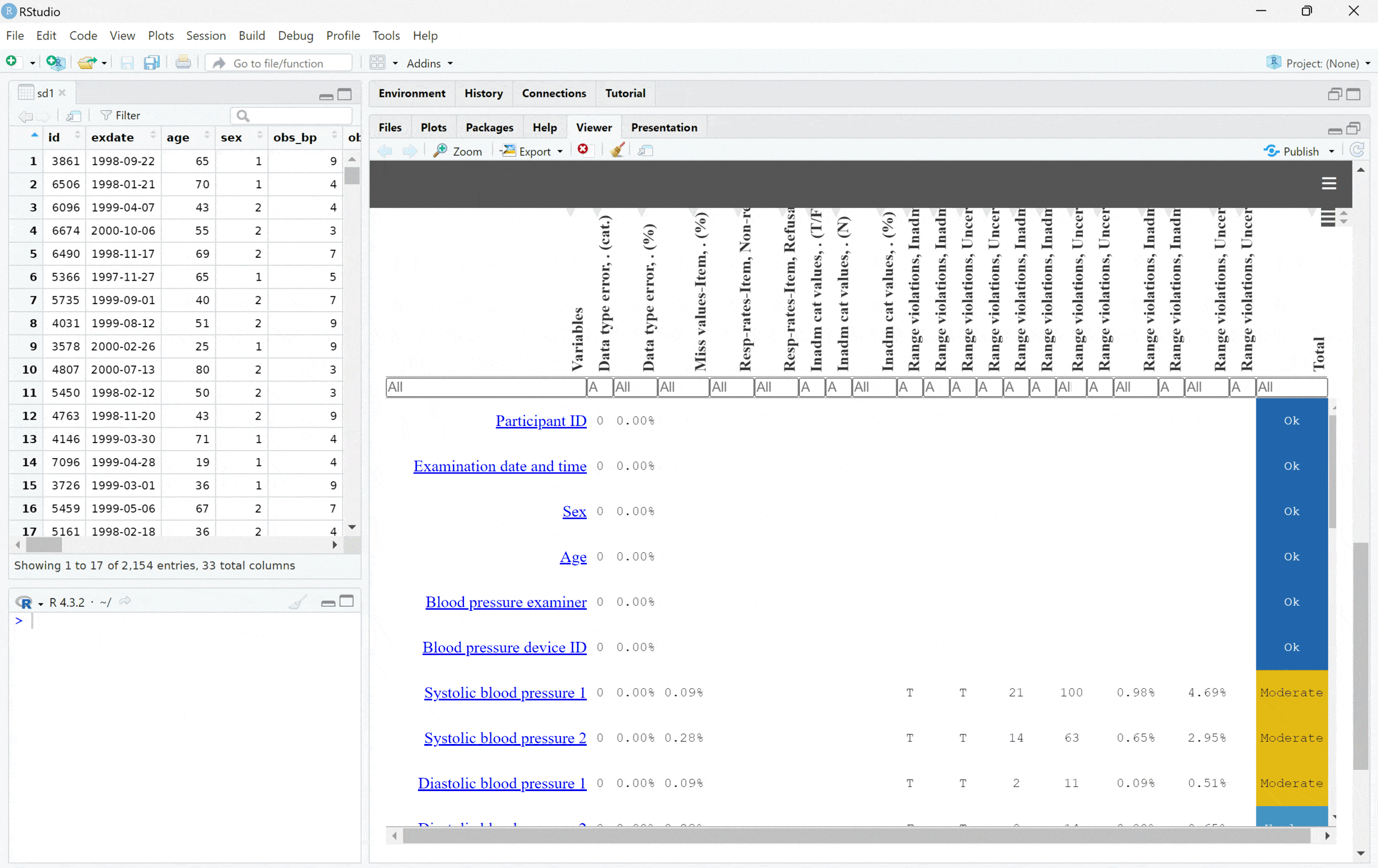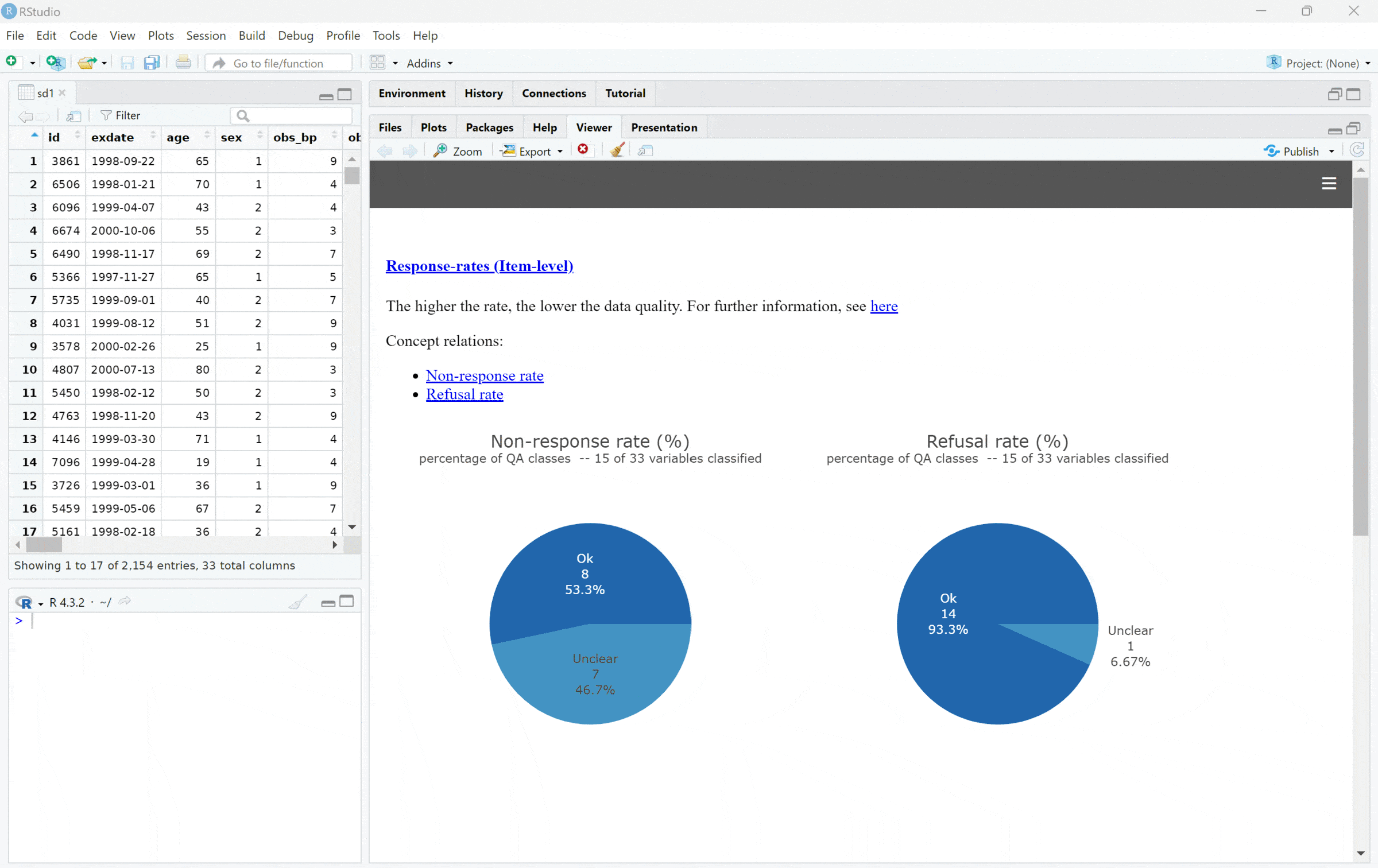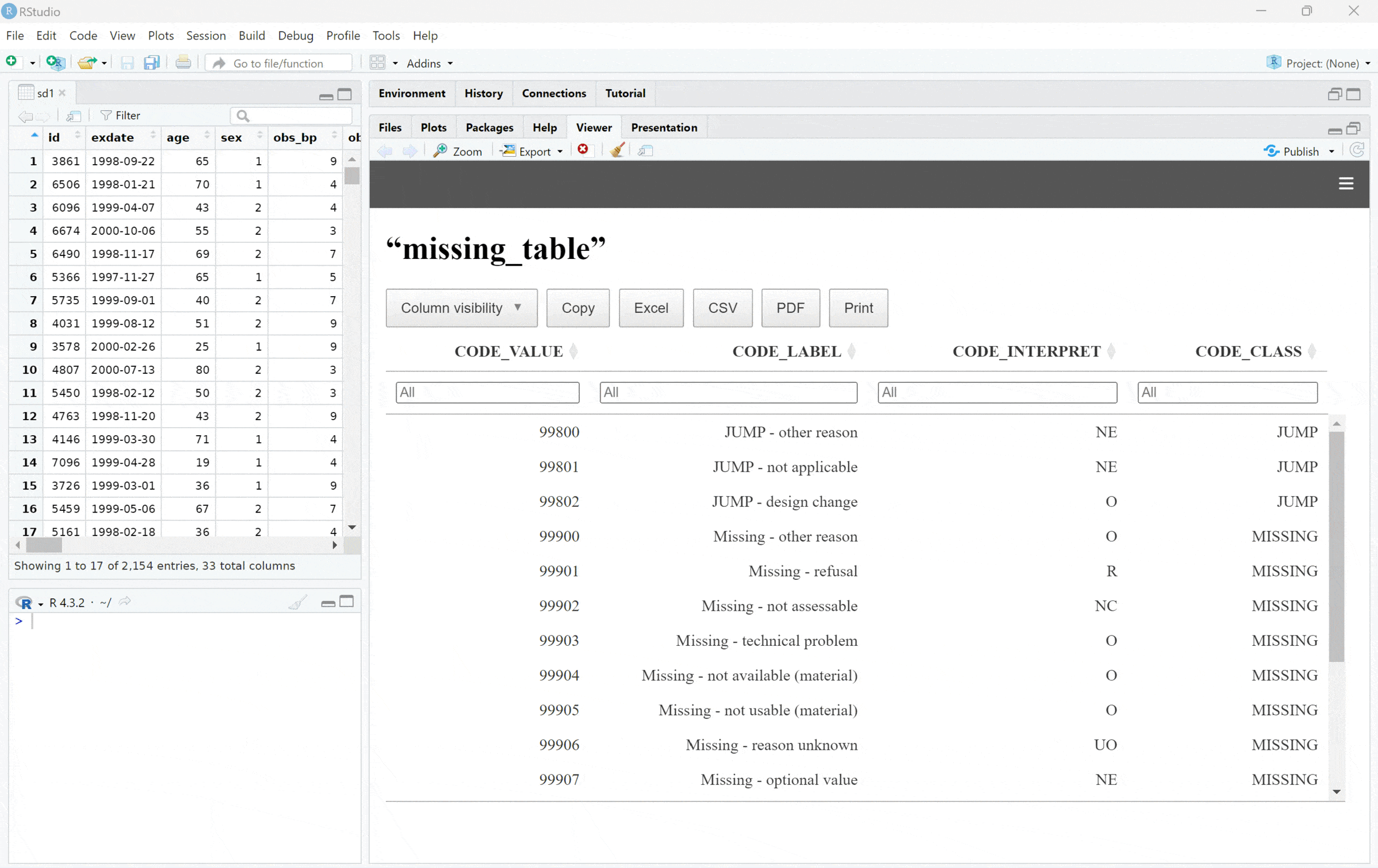
We can create a default report using dq_report2(), which
requires only the data and metadata previously loaded:
my_dq_report <- dq_report2(study_data = sd1) # metadata will be found, if prep_load_workbook_like_file run before.
print(my_dq_report)Minimal workflow example
The animation below shows a quick workflow for reporting data quality with dataquieR:
The report is a mini web page (HTML format) that can be viewed in any
browser. You can see the example report generated by
dq_report2() here.
Example code
The code shown in the animation to produce a report is given here:
# Quick data quality reporting with dataquieR
# Installation
install.packages("dataquieR")
# For further information and to install the development version
# please see our website: https://dataquality.ship-med.uni-greifswald.de/DownloadR.html
# Load the package
library(dataquieR)
# Load the data (Study of Health in Pomerania example data)
sd1 <- prep_get_data_frame("ship")
# View the data
View(sd1)
# Load the metadata
prep_load_workbook_like_file("ship_meta_v2")
# Compute a report
my_dq_report <- dq_report2(study_data = sd1,
meta_data_v2 = "ship_meta_v2",
label_col = LABEL)
# View the results
print(my_dq_report)The function dq_report2() and print() can
manage further arguments and settings. However, this sparse version is a
good start to gaining insight into the data and may serve as the base to
tailor more specific reports.
